

住宅代理 最热
最热
人性化爬行,无IP屏蔽。享受来自220多个地点的9000万个真实ip

大规模查找、验证、收集和丰富企业级多模态数据
只需几个简单步骤即可获取清晰、结构化的 YouTube 数据。

搜索视频和播放列表

从搜索结果中提取视频 ID

用视频元数据丰富结果

下载视频/音频内容

检索视频转录文本
1import requests2import json34def main():5 client = requests.Session()6 target_url = "https://scraperapi.thordata.com/video_builder"78 spider_parameters = [9 {10 "url": "https://www.youtube.com/watch?v=PP935RI48v0"11 }12 ]1314 spider_parameters_json = json.dumps(spider_parameters)15 16 spider_universal = {17 "resolution": "360p",18 "is_subtitles": "true",19 "subtitles_language": ""20 }2122 spider_universal_json = json.dumps(spider_universal)23 24 form_data = {25 "spider_name": "youtube.com",26 "spider_id": "youtube_video_by-url",27 "spider_parameters": spider_parameters_json,28 "spider_universal": spider_universal_json,29 "spider_errors": "true",30 "file_name": "{{TasksID}}"31 }3233 headers = {34 "Authorization": "Bearer Token-ID",35 "Content-Type": "application/x-www-form-urlencoded"36 }3738 try:39 resp = client.post(target_url, data=form_data, headers=headers)40 resp.raise_for_status() # Raises an HTTPError for bad responses41 42 print(f"Status Code: {resp.status_code}")43 print(f"Response Body: {resp.text}")44 45 except requests.exceptions.RequestException as e:46 print(f"Error sending request: {e}")4748if __name__ == "__main__":49 main()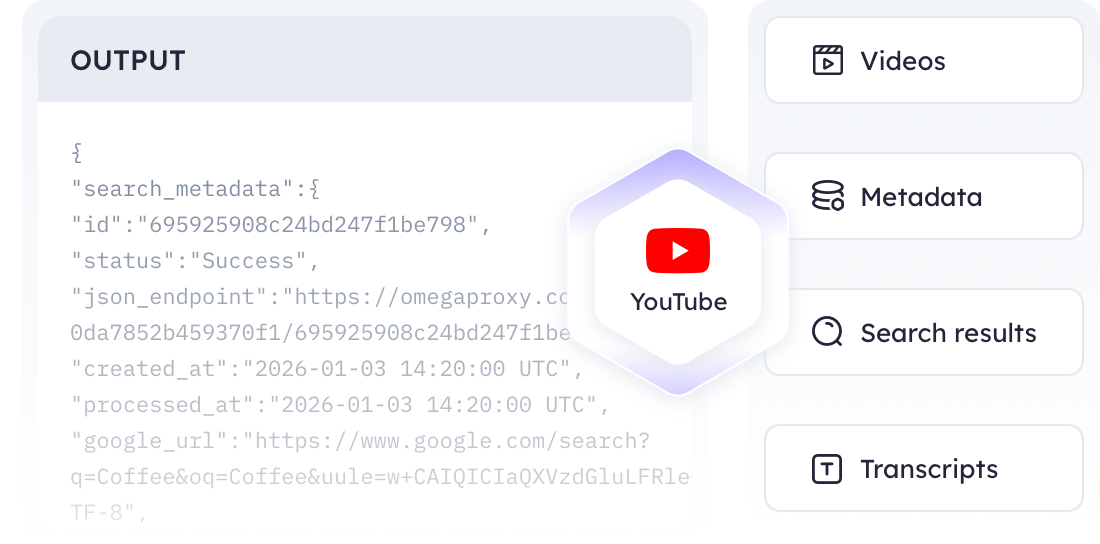
我们提供结构化、AI 兼容的数据,使 YouTube 视频、转录文本、字幕、元数据和搜索结果准备好无缝集成到 LLM、AI 模型和分析工作流中。

我们的平台遵循全球合规标准,包括 GDPR 和 DMCA 法规。我们仅收集公开可用的数据,自动阻止受限内容,并确保安全的加密数据传输和存储。
最好的代理之一。全球活跃的IP超过9000万。选择任意国家或城市的IP地址。
我们正在寻找一个可靠的住宅代理解决方案,能够快速方便地访问数据。比较多个选项后,Omegaproxy 脱颖而出,完美满足我们的业务需求。
网络基础设施工程师
我们的团队需要一个强大的住宅代理服务结合高效的数据获取工具。在所有评估的供应商中,Omegaproxy 正好提供了我们所需要的。
数据分析师
我们需要一个一体化解决方案,同时提供住宅代理和快速数据访问。Omegaproxy 证明是市场上最合适、可靠的选择。
系统管理员
我们公司的运营高度依赖高质量住宅代理和顺畅的数据访问。评估多家供应商后,我们发现 Omegaproxy 是理想的合作伙伴。
后端开发工程师
我们正在寻找基于住宅代理的可靠工具集,提供极速数据访问。Omegaproxy 证明是最符合期望的解决方案。
网络安全专家
我们需要一个全面的平台,支持住宅代理并能即时访问数据。在市场上的所有选项中,Omegaproxy 是唯一满足所有需求的。
DevOps 工程师