

Residential Proxy HOT
HOT
Humanized crawling, no IP shielding.Enjoy 90M real IPs from 220+ locations

Find, validate, collect, and enrich enterprise-grade multimodal data at scale
Just a few simple steps to get clear, structured YouTube data.

Search for videos and playlists

Extract video IDs from search results

Enrich results with video metadata

Download video/audio content

Retrieve video transcripts
1import requests2import json34def main():5 client = requests.Session()6 target_url = "https://scraperapi.thordata.com/video_builder"78 spider_parameters = [9 {10 "url": "https://www.youtube.com/watch?v=PP935RI48v0"11 }12 ]1314 spider_parameters_json = json.dumps(spider_parameters)15 16 spider_universal = {17 "resolution": "360p",18 "is_subtitles": "true",19 "subtitles_language": ""20 }2122 spider_universal_json = json.dumps(spider_universal)23 24 form_data = {25 "spider_name": "youtube.com",26 "spider_id": "youtube_video_by-url",27 "spider_parameters": spider_parameters_json,28 "spider_universal": spider_universal_json,29 "spider_errors": "true",30 "file_name": "{{TasksID}}"31 }3233 headers = {34 "Authorization": "Bearer Token-ID",35 "Content-Type": "application/x-www-form-urlencoded"36 }3738 try:39 resp = client.post(target_url, data=form_data, headers=headers)40 resp.raise_for_status() # Raises an HTTPError for bad responses41 42 print(f"Status Code: {resp.status_code}")43 print(f"Response Body: {resp.text}")44 45 except requests.exceptions.RequestException as e:46 print(f"Error sending request: {e}")4748if __name__ == "__main__":49 main()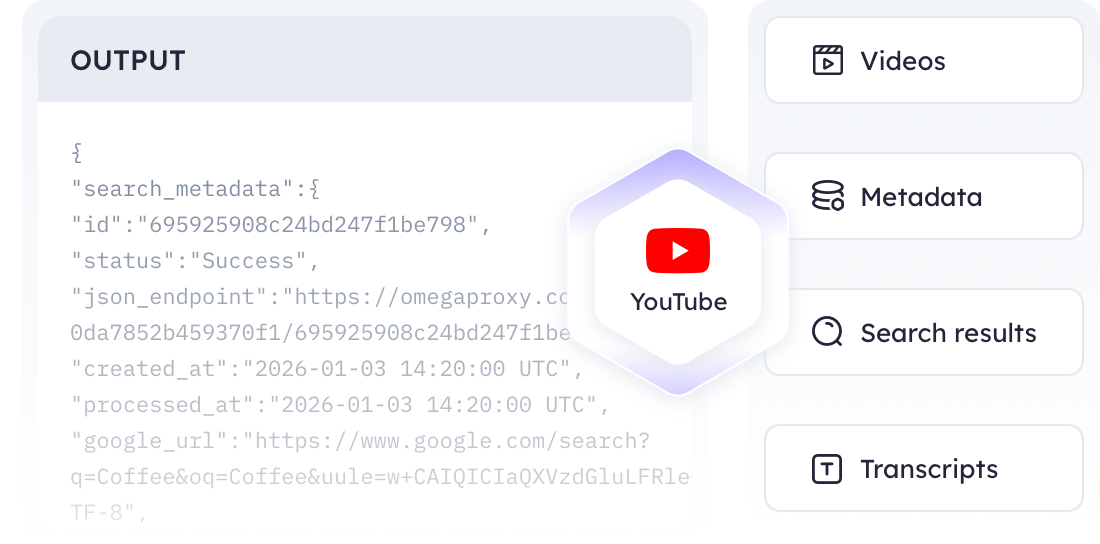
We deliver structured, AI-compatible data, making YouTube videos, transcripts, subtitles, metadata, and search results ready for seamless integration into LLMs, AI models, and analytics workflows.

Our platform follows global compliance standards, including GDPR and DMCA regulations. We collect only publicly available data, automatically block restricted content, and ensure secure encrypted data transmission and storage.
One of the best proxies. More than 90 million IPs are active worldwide. Select an IP address from any country or city.
We were searching for a reliable residential proxy solution with fast and convenient data access. After comparing several options, Omegaproxy stood out as the perfect match for our business needs.
Network Infrastructure Engineer
Our team required a robust residential proxy service combined with efficient data retrieval tools. Among all the providers we reviewed, Omegaproxy offered exactly what we were looking for.
Data Analyst
We needed an all-in-one solution that could deliver both residential proxy capabilities and quick data access. Omegaproxy proved to be the most fitting and reliable choice on the market.
Systems Administrator
Our company’s operations rely heavily on quality residential proxies and seamless data access. After evaluating various providers, we found Omegaproxy to be the ideal partner for our requirements.
Backend Developer
We were looking for a dependable set of tools built around residential proxies with lightning-fast data access. Omegaproxy turned out to be the best solution to meet and exceed our expectations.
Cybersecurity Specialist
We needed a comprehensive platform with residential proxy support and instant data access. Out of all the options on the market, Omegaproxy was the one that checked all our boxes.
DevOps Engineer